Flow Reversal Steering (FRS)
Generalist flow-matching robot policies learn a rich prior over behaviors. These policies contain many skills needed for novel tasks — provided these appropriate behaviors are elicited. How can we use semantic knowledge to steer generalist policies towards sampling "reasonable" actions for new tasks?
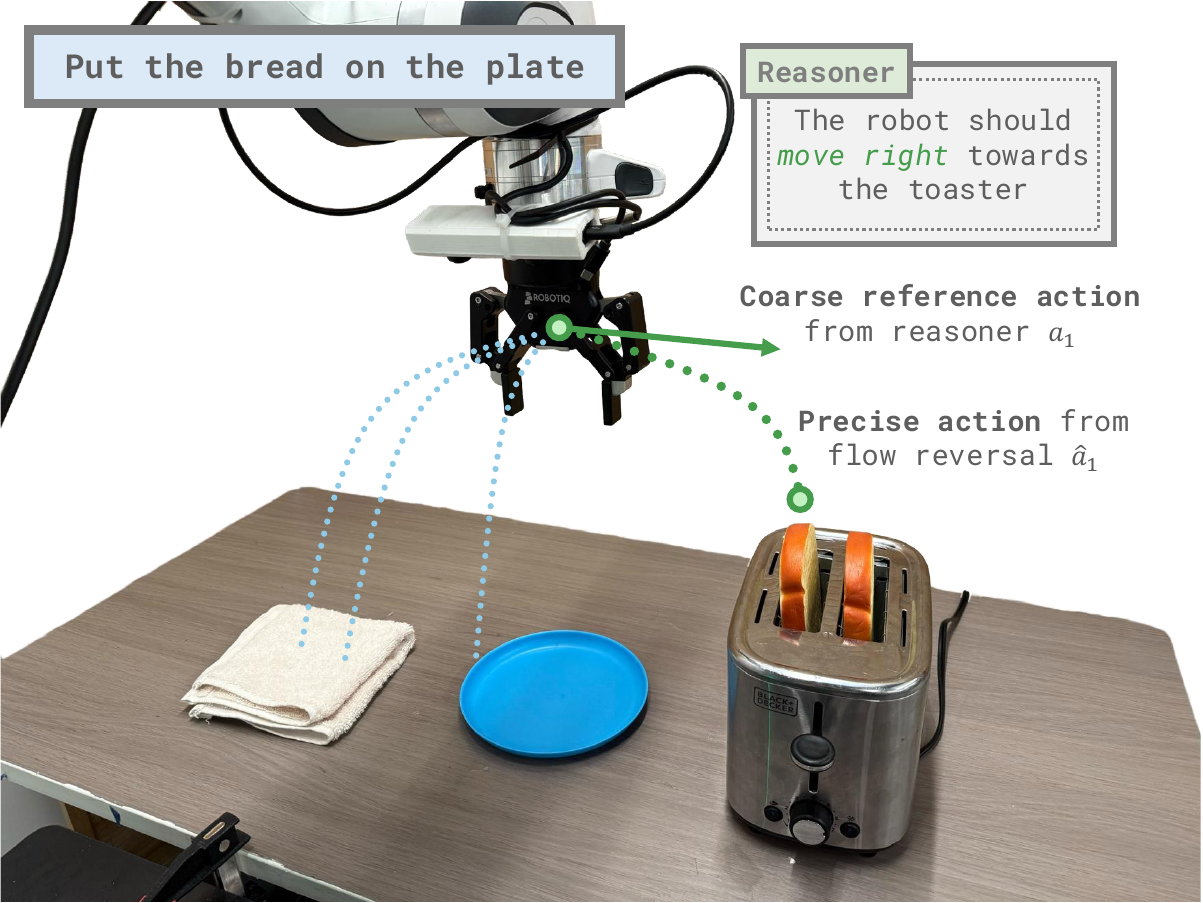
We thus propose Flow Reversal Steering (FRS): a method for guiding generalist flow policies' action sampling by finding underlying noises that map to semantically-reasonable behaviors. By passing a coarse reference action — which captures roughly how the robot should move — through the flow policy in reverse, FRS finds the noise which approximately maps to the action. When subsequently denoised, FRS effectively finds a nearby good behavioral mode from the generalist's prior that is similar to the reference.
# Sample action from flow policy (K integration steps) x ~ N(0, I) # Sample noise dt ← 1 / K for t in 0 … 1: # K forward steps, size dt x ← x + dt·vθ(x, t) return x # action sample
# Steer w/ reference action a_ref (K integration steps) x ← a_ref dt ← 1 / K for t = 1 … 0: # reverse the flow → noise x ← x − dt·vθ(x, t) for t = 0 … 1: # denoise → nearby mode x ← x + dt·vθ(x, t) return x # refined, in-distribution
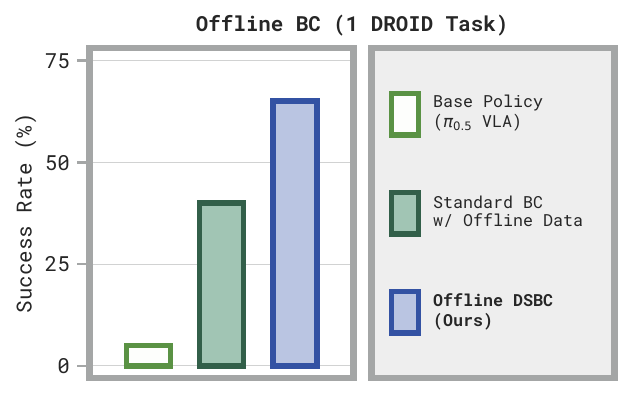
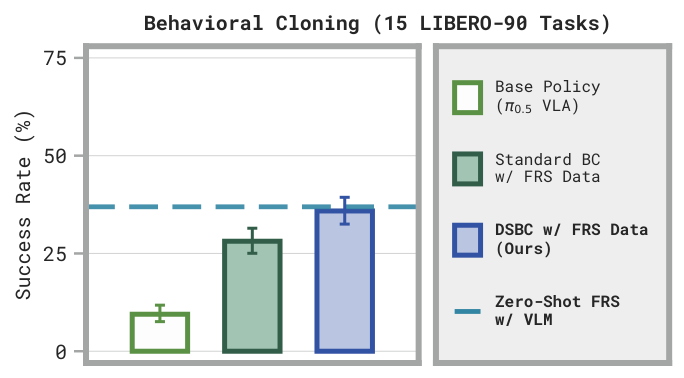
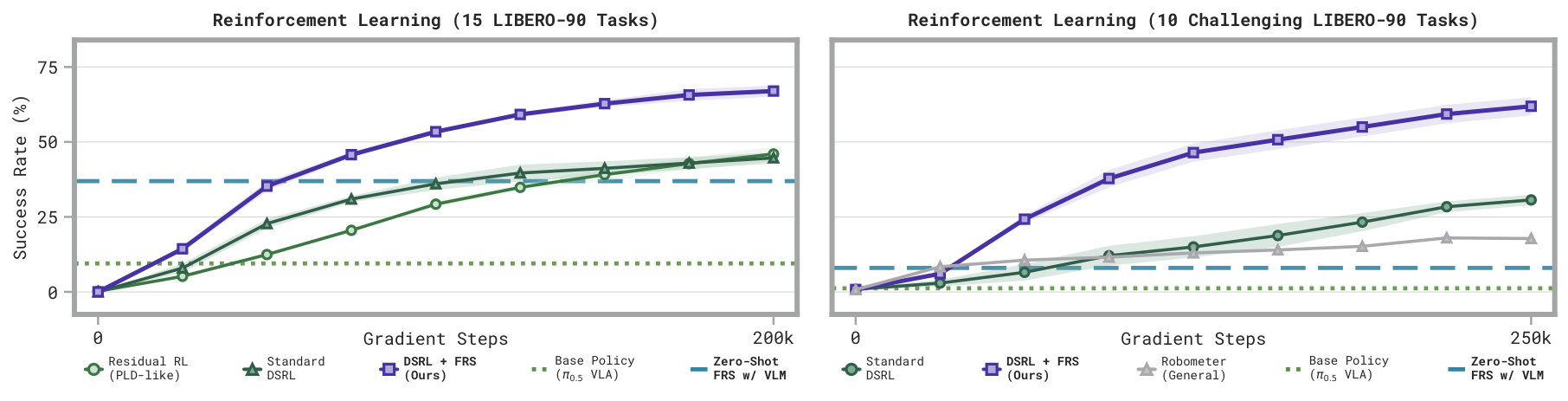
In turn, this allows semantic reasoners, like humans or VLMs, to guide the policy towards task-relevant good behaviors. The noises and actions produced by FRS can also be used for policy learning and improvement, especially via noise-space behavioral cloning and reinforcement learning.

Overview of the FRS pipeline.
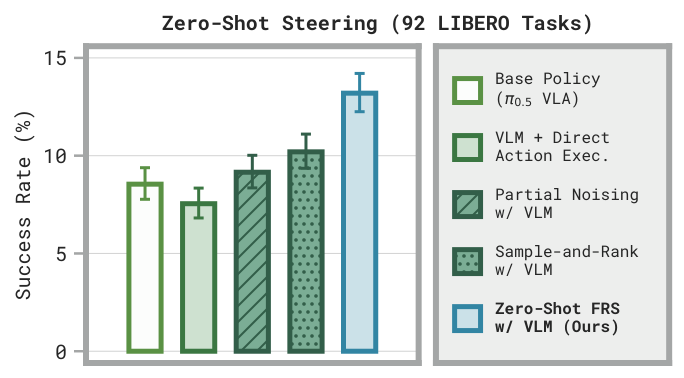
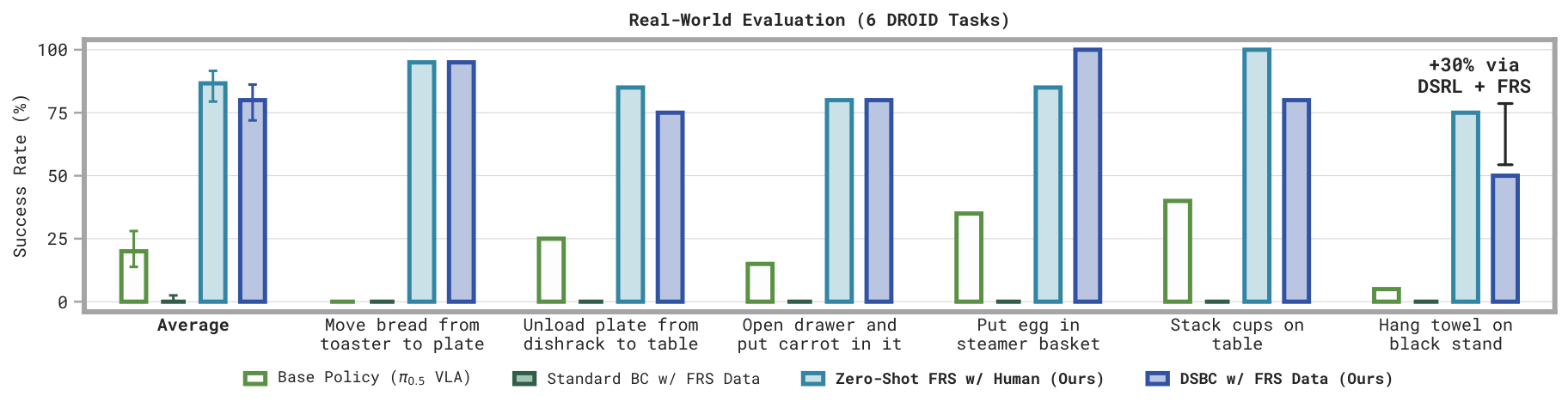
We demonstrate FRS using state-of-the-art π0.5 vision-language-action models (VLAs) in both simulated LIBERO and real-world DROID manipulation tasks. We present three ways to use FRS:
- Zero-shot FRS: directly execute the refined actions FRS elicits from coarse human or VLM guidance, with no additional training.
- Diffusion Steering via Behavioral Cloning (DSBC): distill good noises from flow reversal into a noise policy using supervised learning.
- Diffusion Steering via Reinforcement Learning (DSRL) + FRS: bootstrap noise-space reinforcement learning with FRS rollouts.
Noising with Flow Reversal vs. Forward Diffusion Process
Flow reversal maps data to noise by integrating the flow field backward in time. As flow matching learns a deterministic velocity field, there is a fixed correspondence between noise and data, so the resulting noises denoise back to the original data points.
In contrast, the forward diffusion process linearly interpolates data with Gaussian noise. While this yields the same marginal distributions as flow matching at all times, it does not preserve the exact data-noise correspondence, so the noised points do not necessarily denoise back to the original data.
Interactive Examples of Flow Reversal Steering
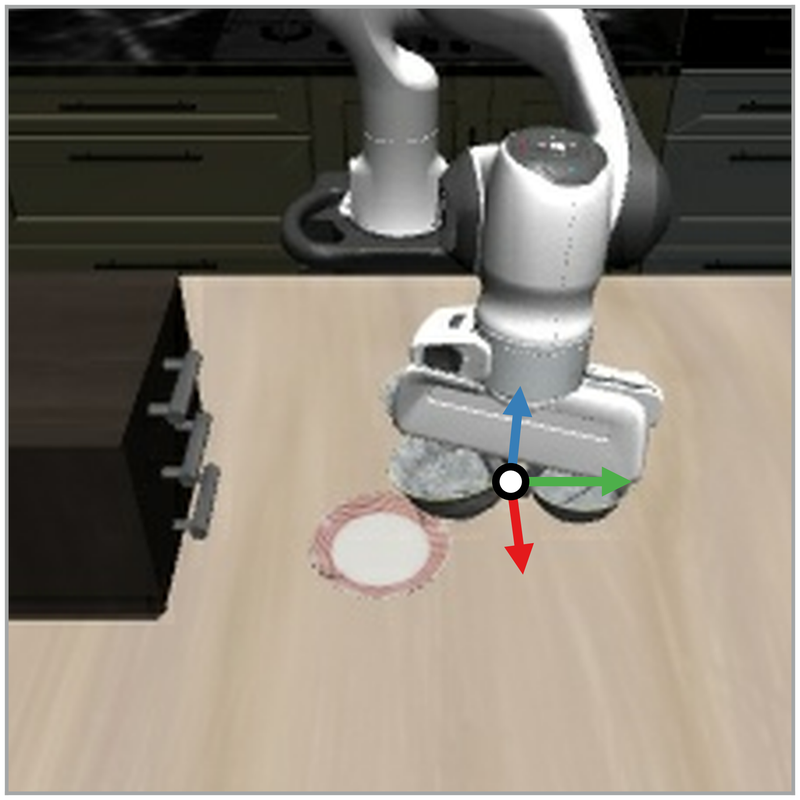
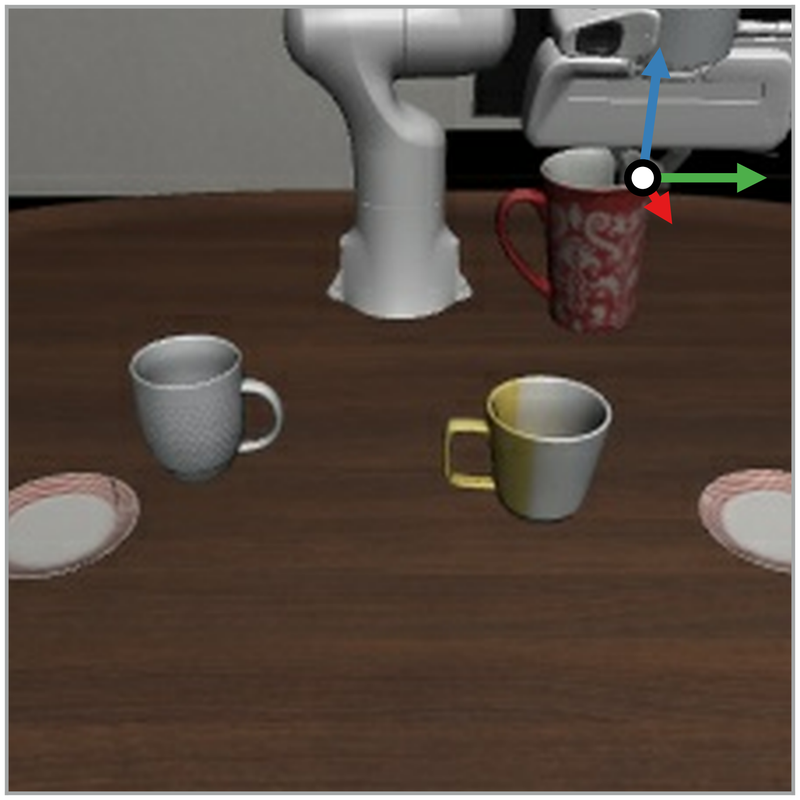
Example LIBERO frames with an interactive 3D view of the cardinal flow-reversal steering directions (arrows) and the resulting steered action chunks (dots). Black dots represent a sample from the VLA without steering, showing that the steered actions do differ from what the VLA usually would output. Three frames are shown per task across the rollout. All actions and steering are done with a π0.5 VLA.